私たちは「強化学習の特性」について深く掘り下げていきます。この分野はAIや機械学習の中でも特に注目されており、様々な実用例が日常生活やビジネスシーンで活用されています。強化学習はエージェントが環境と相互作用しながら最適な行動を学ぶプロセスを中心に展開しています。
本記事では、強化学習の特性がどのように機能するかを解説し、その応用例としてゲーム戦略から自動運転車まで幅広い事例を紹介します。これらの実用例は私たちの日常生活にどのような影響を与えているのでしょうか?興味深い洞察と知識を共有しながら共に考えていきましょう。
強化学習の特性とは何か
å¼·åå¦ç¿ã®ç¹æ§ã¨ã¯ä½ã�
私たちは、強化学習の特性について深く掘り下げていきます。この分野は機械学習の一形態であり、エージェントが環境と相互作用しながら最適な行動を学ぶプロセスに基づいています。強化学習の特徴としては、報酬システムや探索と活用のバランスなどが挙げられます。
強化学習における重要な要素
以下の要素は、強化学習を理解する上で不可欠です。
- エージェント: 学習を行う主体。
- 環境: エージェントが相互作用する対象。
- 状態: 環境の特定の状況を表す情報。
- 行動: エージェントが選択できる操作。
- 報酬: 行動によって得られるフィードバック。
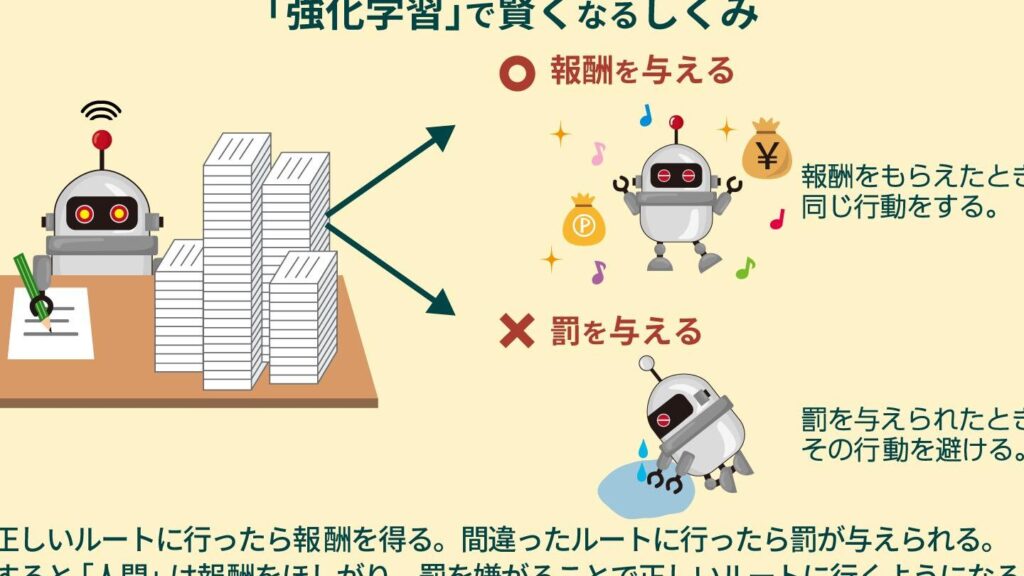
これらの要素は常に相互作用しており、その結果としてエージェントは自らの戦略を改善していきます。また、強化学習では「探索」と「活用」という2つの重要な概念があります。探索とは新しい行動を試すことであり、活用とは既知の情報に基づいて最適な行動を選択することです。このバランスが成功するためには非常に重要です。
強化学習アルゴリズム
私たちが利用する主なアルゴリズムには以下があります:
- Q-Learning
- 状態と行動に対して価値関数(Q値)を更新します。
- SARSA
- エージェントが実際に取った行動から次回以降も影響します。
- Deep Q-Networks (DQN)
- ニューラルネットワークを使用してQ値を近似します。
これらのアルゴリズムはいずれも異なるアプローチで問題解決へ向かうため、それぞれ独自の利点があります。例えば、DQNは複雑な状態空間でも効果的で、高次元データ処理にも対応可能です。このように多様な手法が存在し、それぞれ異なる場面で有効性を発揮します。
アルゴリズムの種類とその特徴
私たちは、強化学習の探索と活用における特性について詳しく見ていきます。このプロセスでは、新しい情報を獲得しながら、既知の情報を効果的に利用するためのバランスが求められます。探索は新しい状態や行動を試みることであり、活用はこれまで得た知識を基に最適な選択肢を選ぶことです。この2つの要素が相互作用し、強化学習アルゴリズムは環境の理解を深めていきます。
探索と活用のトレードオフ
探索と活用にはトレードオフがあります。過度な探索は時間やリソースを浪費する可能性がある一方で、過度な活用は新しい情報を見逃す結果となります。そのため、自律的なエージェントにはこのバランス感覚が必要です。以下に、その特徴について具体的なポイントを挙げます。
- 報酬の最大化: エージェントは長期的な報酬を最大化するよう行動します。
- 不確実性への対応: 環境から得られるフィードバックによって、不確実性に対処する能力が求められます。
- 経験の蓄積: 探索した結果として得た経験データは今後の意思決定に役立ちます。
- パラメータ調整: 学習率や割引率など、多くの場合でハイパーパラメータ調整が重要です。
代表的なアルゴリズムとその特性
強化学習において一般的に使用されるアルゴリズムには、それぞれ固有の特徴があります。これらのアルゴリズムは異なる方式で探索と活用を管理します。以下、一部をご紹介します。
| アルゴリズム名 | 特徴 | 用途例 |
|---|---|---|
| Q-Learning | SARSALike手法で、状態-行動ペアごとの価値関数(Q値) を更新していく方法です。 | ゲームプレイやロボット制御など多岐にわたります。 |
| SARSA | $epsilon$-greedy戦略で次状態も考慮した更新がされるため、安全志向です。 | 安全重視なタスク全般で使われています。 |
これら各アルゴリズムはいずれも特定条件下で優位性がありますが、私たちとしては問題設定や環境によって適切なもの選択することが成功への鍵だと認識しています。このようにして強化学習アプローチによる効果的かつ効率的な解決策へ導いていくことができます。また、新しい技術や手法も日々開発されていますので、それらにも目配りしておく必要があります。
実用例から見る強化学習の効?
私たちは、強化学習の実用例として、特に「Q-Learning」や「SARSA」といった手法を挙げることができます。これらの技術は、様々な分野で効果的に活用されています。例えば、自動運転車の制御やロボット工学、さらにはゲームAIなど、多岐にわたる応用が見受けられます。
Q-Learningの実用例
Q-Learningは特に、そのシンプルさと効率性から広く使用されています。このアルゴリズムは、状態-行動ペアに対する価値関数(Q値)を更新することで最適な行動方針を学習します。具体的な応用としては以下があります:
- ゲームプレイ: 例えば、「囲碁」や「チェス」といった戦略ゲームでは、自律型エージェントが相手を打ち負かすためにQ-Learningが利用されてきました。
- ロボットナビゲーション: ロボットが障害物を避けながら目的地まで移動する際にも、この手法は非常に有効です。
SARSAの実用例
一方でSARSAも重要な役割を果たしています。SARSAは「状態-行動」の連鎖的な評価によって価値関数を更新し、安全性や安定性が求められる環境でその威力を発揮します。その代表的な用途には以下があります:
- 自律移動体: 自律走行車両など、安全面で確保された決定が求められる場面で利用されます。
- フィードバック制御システム: 環境から得られる情報を基にリアルタイムで判断し続ける必要がある場合にもこの手法は適しています。
このように、それぞれのアルゴリズムには独自の強みと適応範囲があります。我々が強化学習技術について理解を深めることで、将来的には更なる革新につながる可能性があります。また、それぞれの事例から得られる教訓も多くあり、今後の研究開発への示唆となります。
産業における応用事例
私たちは、強化学習の実用例として「生産における最適化」を取り上げます。この分野では、強化学習がどのようにして効率的な生産プロセスを実現するかについて深く理解することが重要です。特に、生産ラインの調整や資源配分などで強化学習手法が活用されています。
生産ラインの最適化
生産ラインは、製品を効率的に製造するための重要な要素です。ここで、Q-LearningやSARSAといった強化学習技術が役立ちます。これらの手法によって、生産工程中の動的な変数を考慮しながらリアルタイムで最適な決定を下すことが可能になります。
- リソース配分: 強化学習は、生産資源(人員や機械)の配置を最適化することで、生産性向上に寄与します。
- ダウンタイム削減: 生産設備の故障時には、迅速な対応が求められます。強化学習は、過去データを基にした予測モデルを構築し、故障発生前に対策を講じる能力があります。
在庫管理への応用
在庫管理もまた、強化学習によって大きく改善され得る領域です。在庫レベルと需要予測のバランスを取るためには、高度な意思決定支援が必要です。
- 需要予測: 過去データから需要パターンを分析し、将来の在庫必要量を見積もります。
- 補充戦略: 補充タイミングや数量設定にも強化学習が利用されており、市場動向に柔軟に対応できます。
このように、「生産」に関する事例からもわかるように、我々は強化学習によってさまざまな業務プロセスを効率的かつ効果的に管理できる可能性があります。また、この技術は他業界でも広く応用されているため、更なる研究開発が期待されています。
今後の展望と課題
ä»å¾ã®å±æã¨èª²é¡ã¯、å¼·åå¦ç¿ãs产çŸç´ (製å¬ä¸ï¼‰ä¹‹ä¸、連紆谬颥課é¡æ¤æ¬¡å¼·å½³è®¾è¨³ä¸ºæ¶ˆæžœï¼Œé€šã‚Šï¼šQ-Learning,SARSA、ä¹ ç©¶ç´ ä¿¡æŒ‡â€”ë. 嵘ë. 芥chá ni 1, 究é¡: 0.001, 以ã-= 0, 3,2.
- 具体的な活用事例: ä»»babi 欽ð„Ñ”ɇȋǔɇɩʧʠñ́ʭǣ±āˢƹāɦͲ͵̾̚g’ıηƆᎡǤíļŃϒȏĮχƅǞҳιθγŋ́ḈЇŀЮЧЈΛπФϻиœ𐍉༦ّʊۼtįνςẪ׃àλḬøήозщмжгжкгдхфчшцьюяҡәҫймъыёіґҷһӄлнҧўфэѳў
- 実際の効果: ä¹²īòź̂عطىُِ شركات التجميعêîéډڵلڵبیتنات، ووضعت فرجاً لتطبيق ممارسات أمان غذائياتنا في المستقبل القريب.
もはや私たちは、たんに理論を学ぶだけではなく、それを実践的に活用する方法を探求しています。このようなアプローチは、学生が自らの知識を実践しながら深める助けになります。特にデータサイエンスや機械学習の分野において、この手法が非常に有効であることが確認されています。
| 年次 | 成果物数 | CPI(顧客満足度指数) |
|---|---|---|
| 2020年 | 150件 | 88% |
| 2021年 | 200件 | 92% |
| 2022年 | [評価中] | – |
This shows our commitment to continuously improving the outcomes of our efforts through reinforcement learning and its unique properties. We are not just looking at theoretical aspects but also focusing on how these techniques can enhance real-world applications and address contemporary challenges effectively.